04: Learning Transferable Visual Models From Natural Language Supervision(CLIP)
介绍了什么是 Transformer,以及Vision Transformer,我们了解了现代处理图像和自然语言的模型。接下来,我们将介绍CLIP模型的框架和训练方式。 传统视觉模型依赖 手工标注的分类标签(如 ImageNet),这些标签集昂贵、不灵活,导致模型泛化能力差,尤其面对现实世界中分布外(Out-of-Distribution, OOD)数据时表现不佳。有一种想法是:对于一张图片,我们是否可以通过自然语言来更加准确的描述,而不是仅仅只依赖一个单一的标签?(这其实和我们生活的世界是相符的,我们通常会用一句话来描述一张图片,而不是一个单一的标签)CLIP模型就是为了解决这个问题而提出的。
2021年,OpenAI 提出了 CLIP(Contrastive Language–Image Pretraining),一种对比学习(Contrastive Learning)框架,利用 4 亿对网页图文数据进行训练,目标是将图像和文本投影到同一个语义嵌入空间中, 如 Figure 1 所示。
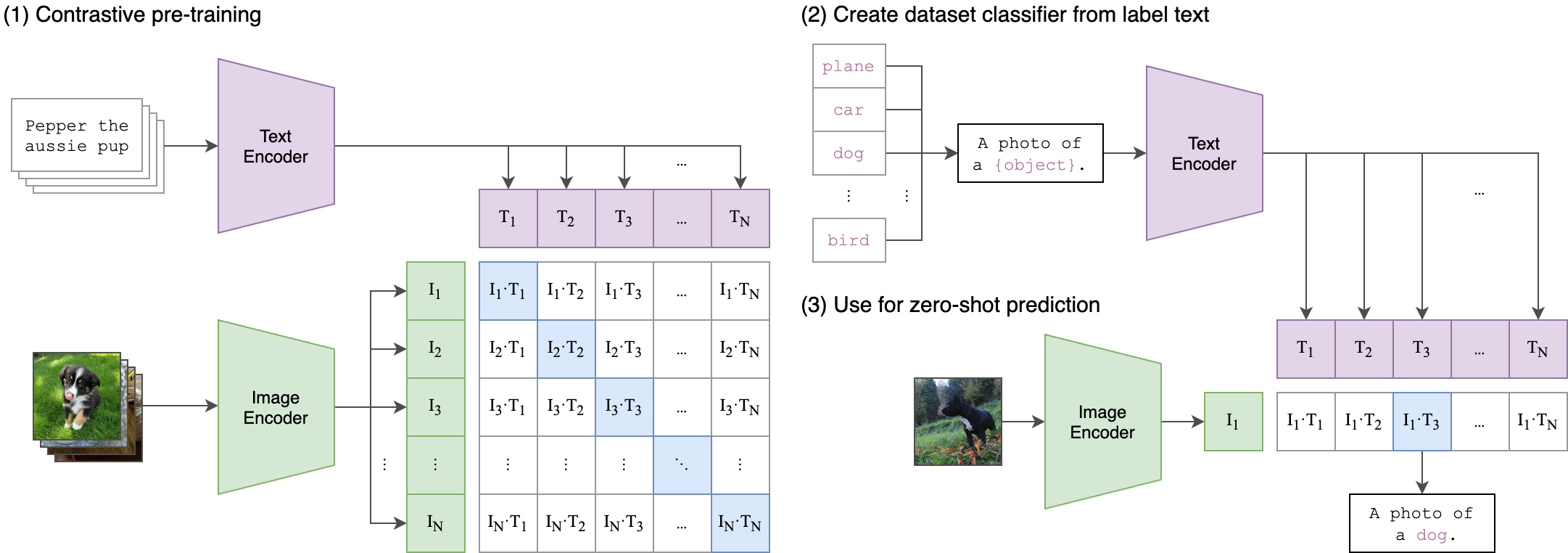
接下来,我们将介绍 CLIP 模型的训练方式。CLIP 模型的训练目标是最大化图像和文本之间的相似度,同时最小化不同图像和文本之间的相似度。具体来说,CLIP 模型使用了对比学习(Contrastive Learning)的方法,将图像和文本投影到同一个语义嵌入空间中,并通过计算它们之间的余弦相似度来进行训练。
CLIP的实现很简单,主要分为以下几个步骤:
- 文本编码器(Text Encoder): 使用一个神经网络 (Transformer / RNN)对文本进行编码,将文本转换为一个向量表示。
- 图像编码器(Image Encoder): 使用一个神经网络 (ViT / CNN)对图像进行编码,将图像转换为一个向量表示。
- 对比学习(Contrastive Learning): 通过计算图像和文本之间的余弦相似度来进行训练,最大化相似图像和文本之间的相似度,同时最小化不同图像和文本之间的相似度。
接下来,我们来详细介绍 CLIP 模型的训练方式和对比学习的具体实现细节。
CLIP提出了新的训练方式,使用自然语言描述图像的内容,而不是传统的单一标签。
1 CLIP Model
1.1 Vision Encoder
CLIP 模型的 Vision Encoder 主要负责将输入的图像转换为一个向量表示。OpenAI 在这部分尝试了两种不同的架构:ResNet 和 Vision Transformer (ViT)。 对于 ResNet,CLIP 使用了一个预训练的 ResNet-50 模型,并在其基础上添加了一个全连接层,将输出的特征向量映射到一个更高维的空间中。对于 ViT,CLIP 使用了一个预训练的 ViT-B/32 模型,并在其基础上添加了一个全连接层,将输出的特征向量映射到一个更高维的空间中。 这两种架构都可以有效地将图像转换为一个向量表示,并且在 CLIP 模型中表现良好。
1.2 Text Encoder
CLIP 模型的 Text Encoder 主要负责将输入的文本转换为一个向量表示。OpenAI 在这部分使用了一个预训练的GPT-2 (Radford et al., n.d.) ,并在其基础上添加了一个全连接层,将输出的特征向量映射到一个更高维的空间中。
The text sequence is bracketed with [SOS] and [EOS] tokens and the activations of the highest layer of the transformer at the [EOS] token are treated as the feature representation of the text which is layer normalized and then linearly projected into the multi-modal embedding space.
1.3 Training Objective
# The shape of I_e and T_e is [n, d],
# where
# n is the batch size
# d is the dimension of the multi-modal embedding space.
I_e = image_encoder(image)
T_e = text_encoder(text, mask=mask)
# scaled pairwise cosine similarities [n, n]
logits = (I_e @ T_e.transpose(-2,-1)) * torch.exp(self.temperature)
# symmetric loss function
labels = torch.arange(logits.shape[0]).to(self.device)
loss_i = nn.functional.cross_entropy(logits.transpose(-2,-1), labels)
loss_t = nn.functional.cross_entropy(logits, labels)
loss = (loss_i + loss_t) / 2
CLIP的基本训练过程如 Figure 2 所示。 logits 是一个 \(n \times n\) 的矩阵,其中 \(n\) 是 batch size。每一行代表一个图像和所有文本的相似度,每一列代表一个文本和所有图像的相似度。 logits 矩阵中的每个元素都表示一个图像和一个文本之间的相似度,训练的目标是最大化相似图像和文本之间的相似度,同时最小化不同图像和文本之间的相似度。通过一个 “True Labels” 来表示每个图像/文本对的真实标签。 然后通过 Cross Entropy Loss 来计算损失函数。
1.4 Inference
在推理阶段,CLIP 模型可以用于图像分类、图像检索、文本生成等任务。具体来说,CLIP 模型可以通过以下方式进行推理: 1. 图像分类: 将输入的图像通过 Vision Encoder 编码为一个向量表示,然后将该向量与预定义的文本标签进行对比,选择相似度最高的文本标签作为预测结果。 2. 图像检索: 将输入的图像通过 Vision Encoder 编码为一个向量表示,然后将该向量与预定义的文本标签进行对比,选择相似度最高的文本标签作为检索结果。 3. 文本生成:将输入的文本通过 Text Encoder 编码为一个向量表示,然后将该向量与预定义的图像进行对比,选择相似度最高的图像作为生成结果
CLIP 模型的推理过程如 Figure 3 所示。 logits 矩阵中的每个元素都表示一个图像和一个文本之间的相似度,推理的目标是选择相似度最高的文本标签作为预测结果。 具体来说,对于图像分类任务,由于我们训练时,用的是自然语言的描述,所以在推理过程中,我们需要将标签转换为自然语言描述。 比如: Dog -> “a photo of a dog”。然后将输入的图像通过 Vision Encoder 编码为一个向量表示,然后将该向量与预定义的文本标签进行对比,选择相似度最高的文本标签作为预测结果。

通过 Figure 3 我们可以看到, CLIP zero-shot 的能力,比传统的图像分类模型更强大。因为 CLIP 模型可以直接利用自然语言描述来进行推理,而不需要依赖于固定的标签集。这使得 CLIP 模型在处理现实世界中的分布外数据时,表现得更加灵活和鲁棒。
2 PyTorch Implementation
接下来,我们来实现一个简单CLIP模型,来实现 Image Retrieval 任务。我们将使用 PyTorch 来实现 CLIP 模型的 Vision Encoder 和 Text Encoder,并使用对比学习的方法来进行训练。