LLM Part1: Pre Training
This is the first part of the LLM series, Pre-training, the Pre-training the most time consuming part of the LLM. In the nutshell, it just the next-word-prediction task. That’s it. Not anything fancy. However, what make the LLM hard to train and only achieve in recent years because it is LARGE. People need to develop and invent some efficient training algorithm to speed up the training process, make it efficient to training and deploying. In the article, I am going to take the path going through the training LLM from scratch, make the LLM easy to understand.
1 Building Blocks of LLM
Same as other models, there are different building blocks for the LLM. Let’s break it down bottom up:
- Tokenization: Convert words into digits
- Embedding: Convert digits into the format that neural network can understand
- Neural Network: The Transformer neural network architecture of the LLM.
- Loss Function: The Cross Entropy Loss is the most common loss function when training LLM
- Optimizer: Most of the LLM is optimized by the AdamW.
- Parallelism: The Large Lanuage Model is larger, which means it hard to fit into the a single machine.
- Inference: After we have trained the model, we need to deploy it to use. However, due to the computing and memory demanding of the LLM. The inference time is slow.
- Evaluation: We need some metrics to measure how well the LLM is doing, and compare between different LLMs.
2 Tokenization
2.1 Word Level
2.2 Byte-Pair-Encoding
2.3 Bit Encoding
2.4 Embedding
Embedding is
3 Nerual Network Architecture
We are going to do the architecture based on Transformer,
3.1 Position Encoding
3.2 Normalization
3.3 Layer Normalization
3.4 RMS Normalization
3.4.1 Post-Norm vs. Pre-Norm
3.5 Without Normalization
Recently, (zhuTransformersNormalization2025?) proposed that we can remove the normalization without harm the performance of the neural network. It replace the normalization layer with a scaled tanh function, named Dynamic Tanh, defined as:
\[ \text{DyT}(x) = \gamma * \tanh(\alpha x) + \beta \]
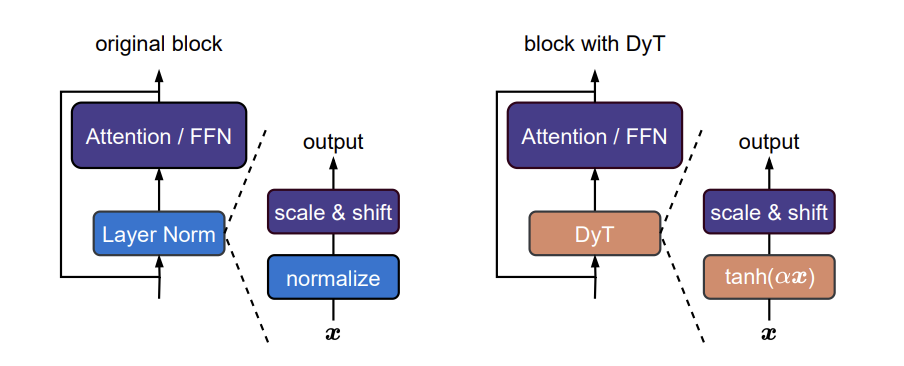
It adjust the input activation range via a learnable scaling factor \(\alpha\) and then squashed the extreme values through an S-shaped tanh function.
3.6 Attention Mechnism
3.7 Feed Forward Network
3.7.1 Mixture of Expert
4 Loss Function
Similar as the other training process, we need a loss function to training and tuning our parameters.
4.1 Cross Entropy Loss
5 Training
5.1 Model Initilization
5.2 Optimizer
5.3 About Gradients
5.3.1 Gradient Accumulations
5.3.2 Gradiant Clipping
5.4 Mixed Precision
5.5 Parallellism
6 Tuning
6.1 Supervised-Fine-Tuning
6.2 Reinforcement Learning from Human Feedback
6.2.1 PPO
6.2.2 DPO
6.2.3 GRPO
7 Inferrence
7.1 Quantization
7.2 Knowledge Distillation
8 Evaluation
9 Fine-Tuning LLM
9.1 Prompt Enginnering
9.2 Prefix-Tuning
9.3 Adapter
9.3.1 LoRA
9.3.2 Q-LoRA
10 Multi Modality of LLM
11 Applications of LLM
11.1 ChatBot
Most know ChatGPT,