LLM Overview
1 What is the Large Language Model
A language model is nothing model that outputs a probability distribution over the next token in a sequence given the previous tokens in the sequence, mathematically, it denoted as:
\[ P_{\theta}(x_t | x_{1:t-1}) \tag{1}\]
Nowaday, when we say a LLM, we usually mean a decoder model, which mean predict the next token based on the previous tokens. However previous, there is another type of the model, not only depends on the previous tokens, but also depends on other conditions, such as, other language for the machine translation task, which denoted as:
\[ P_{\theta}(x_t | x_{1:t-1}, z) \tag{2}\]
In the blog, we mainly focus on the first type, which has the form of Equation 1. The second type is not the focus of this blog, but we might mention it in the future blog. There two main steps of the training an LLM, the pre-training and fine-tuning. The pre-training is the most time consuming part of the LLM. In just the next-word-prediction task. After we have the pre-trained model, the model can only generate the next word based on the previous words. So, we need to fine-tune the model to make it output the desired output. This the job of the post-training. In the post-training, there are two main tasks, the supervised fine-tuning(SFT) and reinforcement learning from human feedback(RLHF). The SFT is the supervised fine-tuning, which is the most common way to fine-tune the model. The RLHF is a new way to fine-tune the model, which is more efficient than the SFT.
2 Tokenization
First question is: how does a machine understand the language? This is the jobs of tokenizer. A tokenizer takes text and turns it into a sequence of discrete tokens. There are four different level of tokenization: - Byte-level - Char-level - Subword-level - Word-level The most common tokenization is the subword-level tokenization, which is the BPE. The BPE is a greedy algorithm that iteratively replaces the most frequent pair of bytes in the text with a new byte. The BPE is a good trade-off between the word-level and char-level tokenization. The word-level tokenization is too large, and the char-level tokenization is too small.
The tokenizer just a huge dictionary that map each word(sub-word) into a unique integer. Those integer later convert to a huge One-Hot vector, which is the input of the embedding layers. Another role of the tokenizer is receiving the unique integer and convert it back to the word(sub-word).
3 Pre-Training
The goals of pre-training (the first stage of training) are to get the language model to: - learn the structure of natural language - learn humans’ understanding of the world (as encoded in the training data) In the nutshell, in the pre-training stage, we “zip” the whole internet into a single file. That’s why the pre-training is so time consuming.
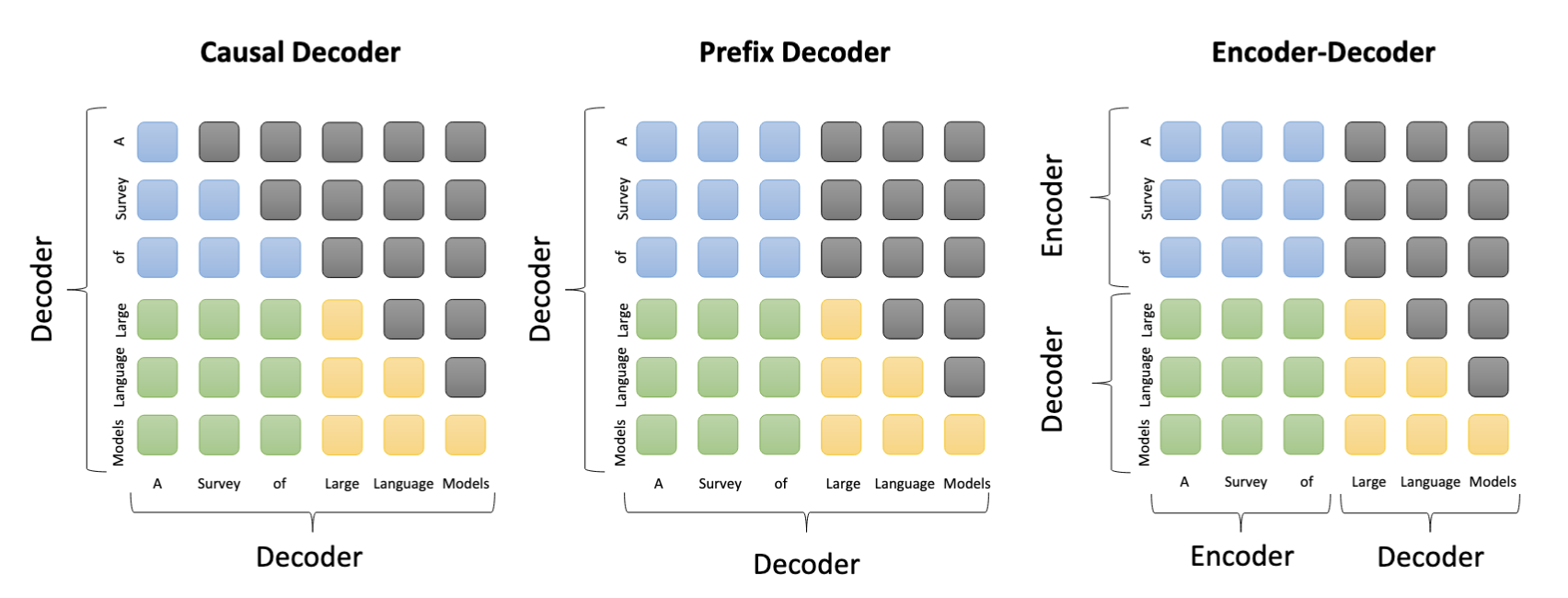
4 Post-Training
4.1 Supervised Fine Tuning (SFT)
4.2 Reinforcement Learning from Human Feedback (RLHF)
5 The emergence abilities of LLM
Ok, so llm take a long time, large dataset to train, why it become so popular? - In-Context Learning - Zero-Shot Learning - Few-Shot Learning
6 Multi Modality LLM
So far, the LLM can only handle text. We know the world is not just words, it also has images, voice, actions, etc. So, we need to make the LLM multi-modal. The multi-modal LLM can handle different types of data, such as text, images, and audio. The multi-modal LLM can be used for different tasks, such as image captioning, visual question answering, and text-to-image generation.